Az OpenAI ChatGPT áttörő sikerét követően a nagy nyelvi modellek (LLM) és a rájuk épülő mesterséges intelligencia-alkalmazások viharszerűen meghódították a világot. A 2022 novemberében nyilvános használatra bocsátott ChatGPT a nagy teljesítményű, több mint 175 milliárd paramétert tartalmazó, 3.5 LLM GPT-re épült. Néhány hónapon belül, 2023 februárjában a Meta kiadta a Llama modelltechnológiáját, mely egy szerényebb paraméterszám mellett is lenyűgöző teljesítményű LLM volt. A kérdés, hogy a nagy teljesítményű mesterséges intelligenciamodelleket nyíltan közzé kell-e tenni, azóta is felvetődik, még akkor is, amikor számos más, a GPT 3.5 képességeit elérő vagy meghaladó LLM követte ezeket.

A nyilvános érvek általában „binárisan” kezelik a kérdést. A nyílt forráskódot pártolók azt állítják, hogy a nyílt forráskód kritikus fontosságú az innováció, a modellek teljesítményének vizsgálata és annak megakadályozása szempontjából, hogy a mesterséges intelligencia üzletág néhány nagy piaci tőkeértékű technológiai vállalat kezében összpontosuljon. A nyílt forráskódot ellenzők az LLM-ek és kimeneteik manipulációs és megtévesztő erejére hivatkoznak, valamint azokra a veszélyekre, melyeket ez a közbiztonságra és a nemzetbiztonságra jelent. Ahogy a legtöbb technológia nóvum esetében történni szokott, az igazság valahol most a kettő között van. Mind a pro, mind az ellenzéki nézőpont olyan feltételezéseken alapul, melyek alaposabb vizsgálatot igényelnek. Érdemes így ezt a vizsgálatot a következő szempontok alapján elvégzni: mit sugall a nyílt forráskódú szoftverfejlesztés története a nyílt forráskódú mesterséges intelligencia innovációs előnyeiről, valóban „nyílt forráskódúak”-e az eddig nyíltan kiadott LLM-ek (és hogy ez számít-e vagy sem), és ha a nagy teljesítményű mesterséges intelligencia technológia nyílt kiadása egyáltalán bölcs dolog lenne, milyen védőkorlátoknak lehet értelme velük kapcsolatban.
A nyílt forráskódú szoftverek történelmi jelentősége
A nyílt forráskódú szoftver (OSS) mozgalom hihetetlenül sokat tett az innovációért a technológiai iparban. A szoftverfájlok, modulok és teljesen integrált programok szinte minden elképzelhető alkalmazáshoz könnyen letölthetők a világhálón található weboldalakról és tárolókból. Az aggregátorok (pl. SourceForge, GitHub), a projektgazdák (pl. Linux Kernel, Apache Foundation) és az érdekvédelmi szervezetek (Free Software Foundation, Linux Foundation, Open Invention Network) mind megkönnyítették az OSS elérhetőségét és használatát a programozók, a vállalatok és a végfelhasználók számára. Az OSS mozgalom az 1990-es években vált ismertté, válaszul a személyi számítógépek forradalmát hajtó, egyre nagyobb befolyással bíró operációs rendszer és alkalmazásszoftverek feletti tulajdonosi ellenőrzésre. Akkoriban az IBM, az Apple és a Microsoft voltak a „nagy játékosok”, akiknek operációs rendszerei a vállalati és személyi számítógépeket is működtették. Az internet megjelenésével az 1990-es évek közepén a Linux vált az adatközpontok által vezérelt elosztott számítástechnika alternatív operációs rendszerévé, mely a web infrastruktúráját alkotó szervereket, routereket és egyéb eszközöket működteti.
A Linux forradalma akkor jött létre, amikor összejött a motiváció és az eszköz, hogy megszervezze több ezer, globálisan elosztott, független programozó erőfeszítéseit. Ezek a programozók teljes mértékben önkéntes munkában vettek részt, és nem csupán egy olyan operációs rendszer létrehozására törekedtek, mely különbözik például a Microsoft Windows-tól, hanem mely jobb, megbízhatóbb, rendszeresebben frissül és gyorsabban is fejlődik. Mivel az erőfeszítés csak programozói szakértelmet, önkéntes munkaidőt és hatalmas kurátori erőfeszítést igényel, a Linux fejlesztésének, terjesztésének és használatának nem voltak költségkorlátozó tényezői. Az OSS elterjedése és elfogadása a mobil számítástechnika forradalmának megjelenésével folytatódott a századfordulón. Azóta is szorosan összekapcsolódik minden olyan nóvum fejlesztésvel, mint a dolgok internete (Internet of Things, IoT) és szinte minden „intelligensnek” nevezett mai eszköz (termosztátok, órák és hasonlók).
Az OSS koncepciója sok nagy technológiai vállalat számára ellenszenves volt, amikor a mozgalom az 1990-es években először kezdett érdemi hatást gyakorolni az iparágra. Mivel a mozgalom az egyre hasznosabb és szélesebb körben elterjedt számítástechnikai eszközök futtatásához szükséges szoftverek koncentrált tulajdonosi ellenőrzésének ellensúlyozására jött létre, sokan fenyegetésnek tekintették. Steve Ballmer, a Microsoft korábbi vezérigazgatója 2001-ben a Linux operációs rendszert „rákos daganatnak” nevezte, mely „szellemi tulajdonjogi értelemben mindenre rátapad, amihez hozzáér”. Gyorsan eljutottunk Satya Nadella vezérigazgató korszakába. Tekintettel az OSS-alapú platformok és eszközök óriási előnyeire az Azure felhőüzletágban, melynek ő maga volt az úttörője, a Microsoft az elmúlt években egészen figyelemre méltó módon megváltoztatta ezt az ellenséges hangnemét.

A szerzői jog volt a szellemi tulajdonjog elsődleges formája a szoftver forráskódjának védelmére (a forráskódot, mint írott utasítást, a szerzői jog az irodalmi művekhez hasonlóan kreatív kifejezésként kezeli). Az OSS megosztására használt licencszerződések formái „copyleft”-nek minősültek (fordított szerzői jog), mivel a szerzői jog által biztosított tulajdonosi ellenőrzést a feje tetejére állították. A nyílt forráskódú licencek alapjául szolgáló alapvető „copyleft-mechanizmus” a szerződési jog elveinek és a szerzői jog által biztosított jogoknak a kombinált alkalmazása a forráskód széles körű, minimális korlátozásokkal történő megosztásának elősegítésére. Az ezekben az engedélyekben jellemzően szereplő kötelezettségek a nyitottság előmozdítását szolgálják, például megkövetelik, hogy az engedélyesek a forráskód szerzőségét a tulajdonosi jogok megőrzésével tiszteletben tartsák, biztosítják, hogy az érintett OSS minden későbbi címzettje tiszteletben tartsa és továbbadja a licencfeltételeket az újraelosztás során, és engedélyezik az eredeti OSS-ekből származó művek létrehozását, különösen a nyilvánosan megosztott fejlesztések esetében.
A nyílt forráskódú szoftverek mozgalma az elmúlt négy évtized nagyszabású technológiai fejlődésének előmozdítása mellett támogatta a megosztott problémamegoldás, az önkéntes technológiafejlesztés és a technikai tudásmegosztás kultúráját is. Ebből az akadémiai kutatók, diákok és „hobbisták”, valamint a hivatásos programozók, a technológiai vállalatok és a végfelhasználók egyaránt profitáltak. Túlzás nélkül állíthatjuk, hogy az OSS felelős az általunk ismert modern technológiai iparért. Az OSS mozgalom a tanulás és a szoftverek körüli széles körű társadalmi hasznosság előmozdításának egalitáriusabb megközelítését eredményezte, mely a társadalomtudományokat és a már tudományokat is beleértve minden területre átterjedt.
Az Android mint összehasonlítási alap
Tekintettel az OSS átütően pozitív hatására, természetesen felmerülhet a kérdés: „Miért ne terjeszthetnénk ki a technológiafejlesztés nyílt forráskódú módját a mesterséges intelligenciára?”. A nyílt kiadású mesterséges intelligencia mellett érvelők általában az OSS erényeinek fentebb vázolt általános ismertetésére hivatkoznak. A következő vita lényege nem az, hogy aláássuk az LLM-ek nyílt fejlesztése mellett szóló érveket, hanem egyszerűen csak az, hogy mérsékeljük az OSS mozgalom történelmi erényeinek a mesterséges intelligencia iparági kontextusára gyakorolt hatását érintő feltételezéseket. 2007 novembere előtt, amikor a Google először adta ki béta verzióban a Linux-alapú Android mobil operációs rendszert, a nagy technológiai vállalatok ritkán adtak ki nagyobb szoftvertermékeket nyílt forráskódú licencek alatt (ez alól a Sun Microsystems, melyet azóta az Oracle felvásárolt, jelentős kivételt képez). Inkább az olyan vállalatok, mint a Red Hat, melyet azóta az IBM felvásárolt, segítettek a nagyvállalatoknak a Linuxhoz hasonló termékek bevezetésében és integrálásában.
Az Android esetében figyelemre méltó, hogy OSS-ként jelent meg egy olyan mobilipari szegmensben, melyet a szabadalmaztatott technológia és gyakorlat jellemez. A Google számára a lehetőség az volt, hogy támogassa a mobilkészülékek gyártóit, akiknek termékeit az Apple 2007 júniusában, az iPhone első megjelenésével gyorsan felforgatta. Az Android lehetőséget biztosított ezeknek a gyártóknak, hogy talpon maradjanak a rendkívül kaotikus mobil számítástechnikai piacon, ahol az érintőképernyő-orientált alkalmazások és a webböngészés a hétköznapi felhasználók számára is keresletet teremtett. Ezt megelőzően az üzleti felhasználók biztosították az alkalmazásokat és a webböngészést támogató mobileszközök értékesítését és nyereségességét (emlékeznek még a Blackberry és a Palm készülékekre?).
A Google nem rendelkezett olyan fejlesztői közösséggel, mely hozzájárulhatott volna az Android alapvető fejlesztéséhez, frissítéséhez és továbbfejlesztéséhez. A fejlesztés nagy részét egyszerűen házon belül végezte, és az operációs rendszert a fejlesztők, főként a mobilkészülék-gyártók számára tette elérhetővé. (A Google szervezi az Open Handset Alliance nevű konzorciumot, melynek tagjai szintén hozzájárulnak az Android fejlesztésének egyes aspektusaihoz. Ezek a tagok azonban nagyrészt mobilkészülék-gyártók, akik tanácsot adnak a hardverükhöz és a saját fejlesztésű alkalmazásokhoz szükséges felhasználói felület fejlesztéséhez).
Az Androidon keresztül a Google nemcsak az Apple iPhone-jának és saját operációs rendszerének (iOS) jelentékeny konkurenciáját tette lehetővé. Biztosította azt is, hogy olyan platformot hozhasson létre a széles körű elterjedés érdekében, mely a mobil számítástechnika korszakában is releváns és széles körben elérhető szolgáltatásokat (mint például a keresés, a YouTube, a hirdetések, a Gmail és a Drive) nyújt. A Google kénytelen egészséges prémiumot fizetni az Apple-nek, hogy az Apple mobilkészülékein az olyan szolgáltatások, mint a Keresés, továbbra is alapértelmezettek maradjanak. Az Android lehetővé teszi a Google számára, hogy ne legyen túlságosan lekötelezettje az Apple-nek, anyagilag és más módon is, hogy alapvető termékeit és szolgáltatásait a felhasználók elé tárja.
A Google a partnereszközökre telepített Android minden egyes példányához saját alkalmazásokat és szolgáltatásokat csatol. Az Android nyílt forráskódúvá és ingyenessé tétele lehetővé teszi a készülékgyártók számára, hogy elkerüljék a mobil operációs rendszerek saját fejlesztésű karbantartásának és fejlesztésének költségeit. Ezzel egyidejűleg a Google megtéríti saját Android-fejlesztési és karbantartási költségeit azáltal, hogy biztosítja, hogy alapvető alkalmazásai és szolgáltatásai a forgalomban lévő mobileszközök többségén az Android-élmény szerves részét képezik. Az Android nyílt forráskódúvá tételének további előnye, hogy a fejlesztői közösségben ez a tudatosságot és a Google által felvett mobilmérnöki tehetségek előképzettségét is növeli.
Az Android ezen aspektusait több okból is érdemes megvitatni ebben az összefüggésben. Először is, az Android megtestesítette az OSS teljes vállalati elfogadására való áttérést, nem csupán a belső műveletek támogatására szolgáló eszközkészletként, hanem egy kereskedelmi termék teljes körű termékfejlesztési és forgalmazási stratégiájaként. (A Google is átvette ezt a stratégiát a Chromium, a Chrome webböngésző mögött álló OSS-projekt 2008-as kiadásával). Az Android hatékony ellensúlyt jelentett az iOS-sel szemben, ami előnyös a fogyasztók és általában a mobileszközök ökoszisztémája számára. Az általa létrehozott operációs rendszer-innovációs előnyök azonban nem olyan széles körűek. Amikor a nagy OSS-termékeket elsősorban nagyvállalatok fejlesztik és tartják fenn, a nyílt fejlesztés dinamikája megváltozik. Az alapterméket forgalmazó vállalat a Google-hoz hasonlóan késleltetheti a nyílt forráskód kiadását, amíg nem volt lehetősége arra, hogy egy teljesen integrált terméket hozzon forgalomba. A vállalat maga irányítja az innovációs és termékfejlesztési ciklust. Az OSS-t átvevő külső fejlesztők és leendő versenytársak mindig lemaradnak, és nem fejlesztik, javítják a fedett szoftvert a kibocsátó vállalkozással egyenrangúan. A vállalat által kifejlesztett és karbantartott OSS ökoszisztémáiban tevékenykedők nagymértékben függnek az irányító vállalattól.

Az Android „fork-olt” változatainak túlnyomó többsége nem vezetett versenyképes termékkínálathoz. Az Amazon az egyik legjelentősebb nagyvállalat, mely az Android FireOS nevű, hamisított változatára épített termékeket. A technológiai óriás már évekkel ezelőtt leállította FireOS telefonját, nemrégiben saját operációs rendszert fejlesztett ki, és a hírek szerint a fent vázolt dinamika miatt el is távolodik az Androidtól. Az Android-forkerek által kifejlesztett innovatív funkciók közül sokat a Google egyszerűen visszamásol az alapplatformba (pl. a keret nélküli kijelzők támogatása). Az Androidból elsősorban a Google húz hasznot, a Google által szentesített Android-verziókat elfogadó készülékgyártók pedig csak a „következő legjobb” helyzetben találják magukat. Az elosztott innováció és az operációs rendszerek közötti verseny tekintetében az előnyök innen tekintve meredeken csökkennek.
A nyílt kiadású LLM-ek esetében az Androidhoz hasonló dinamika érvényesül. A mobil operációs rendszerekkel szemben az LLM-ek fejlesztése erősen erőforrás-igényes. Csak egy olyan erős LLM előképzése, mint a GPT 3.5, 175 milliárd paraméterrel, becslések szerint jóval több mint 5 millió dollárba került. A GPT 4 több mint 1 trillió paramétere több mint 100 millió dollár költséget vindikált. Ez még jóval azelőtt van, hogy a kiképzett modell következtetés céljából történő működtetésének (azaz a felhasználói utasítások alapján történő kimenetek létrehozásának) költségeihez érnénk. A jelentések szerint a ChatGPT üzemeltetése tavaly tavasszal naponta több mint 700.000 dollárba került. Ki tudja, hol tart ez a szám most. Valójában csak a nagy, jól felszerelt technológiai vállalatok és a legalább több százmillió dolláros finanszírozással rendelkező startupok engedhetik meg maguknak az LLM platformok képzését, nemhogy működtetését. Viszont csak ezek a szereplők engedhetik meg maguknak, hogy kezdetben nagy teljesítményű LLM-eket képezzenek ki, melyeknek a változatait aztán nyílt kiadású modellként kínálhatják a nyilvánosságnak. (Van néhány egyetemi fejlesztésű, nyílt kiadású modell, mint például a Stanford-i Alpaca és a Vicuna a Berkeley-i székhelyű LMSYS Org-tól, de ezeket a modelleket a Meta Llama LLM-jét használva fejlesztették ki, mint előképzett alapmodellt, majd egyéni finomhangolással egészítették ki. Másképp nem lett volna lehetséges).
Az operációs rendszerekkel ellentétben, melyeket hardvereszközökben való használatra szánnak, az LLM-eket általában „hosztolt platformként” telepítik. Ahhoz, hogy egy LLM-üzemeltető kereskedelmi hasznot húzzon belőle, egyrészt hosztolnia kell egy LLM-et, másrészt pedig olyan alkalmazásokat kell biztosítania, melyek ezeken alapulnak, például chatbotokat és képgenerátorokat. Mint említettük, ezek a tevékenységek költségigényesek, hacsak nem rendelkeznek nagyon jó forrásokkal. Értelemszerűen az LLM-ek nyílt kiadású verzióitól nem várható, hogy ösztönzik majd a versenyt, és az innovációs előnyeik is korlátozottak lesznek, és valószínűleg maguk a kiadók részesülnek csak belőlük. A nyílt kiadásnak ebben a kontextusban még mindig lesznek erényei (például a modellek finomhangolása egyedi alkalmazásokhoz), de ezeket nem szabad túlhangsúlyozni, vagy feltételezni, hogy azok az OSS általánosított történelmi portréjához kapcsolódó erényeket tükrözik.

Kevés nyílt kiadású MI-modell felel meg az OSS iparági kritériumoknak
Ahhoz, hogy „nyílt forráskódúnak” tekintsék, nem elég, ha egy szoftverfájl vagy program forráskódját bármely felhasználó számára hozzáférhetővé teszik, hogy „bütykölhesse” vagy megvizsgálhassa. A forráskódot kísérő licencfeltételek típusának inkább meg kell felelnie bizonyos kulcsfontosságú elveknek. Az Open Source Initiative (OSI) ma az iparági meghatározó abban, hogy milyen licenctípusok számítanak „nyílt forráskódúnak” és milyenek nem. Az OSI az évek során a licencek széles skáláját „áldotta” meg, köztük kiemelkedően a General Public License (GPL) 2. és 3. verzióját, az Apache 2.0 licencet, az MIT licencet és a Berkeley Software Distribution (BSD) licencet. Ezek a licencek mechanikájukban és a közvetlen és a későbbi licenctulajdonosokra rótt kötelezettségek típusaiban meglehetősen eltérőek. A tíz alapelv azonban, amelyeknek meg kell felelniük (a „nyílt forráskód meghatározás”), az alapvető kritériumok.
Az IEEE által az IBM jelentős támogatásával meghirdetett Responsible AI License (RAIL) kezdetén az IEEE által meghirdetett, az MI-val való visszaélés valószínűsége iránti érzékenység vezérelte a kulcsfontosságú feltételek megalkotását, melyek a RAIL hatálya alá tartozó MI-alkotások bármely licencjogosult vagy későbbi felhasználó általi felelősségteljes felhasználását írják elő. Az elfogadható és tiltott felhasználási módok megfogalmazásának megközelítését a nyílt felhasználási licencekkel kapcsolatban a Meta a Llama 2 Community License (L2CL) és a Google a Gemma Terms of Use (ToU) esetében is átvette. Más, a közelmúltban megjelent nyílt kiadású modellek, mint például az Allen Institute OLMo 7-B és Mistral 7B modellje, kontrasztként szolgálnak. Az utóbbi két nyílt kiadás hű az OSS betűjéhez és szelleméhez, és (az Androidhoz hasonlóan) az Apache 2.0 licenc alatt jelent meg. De a felelősségteljes használatra vonatkozó elvárások vagy jogilag kikényszeríthető követelmények nélkül érkeznek. Mint látható, a vizsgált nyílt kiadású licenctípusok közül csak az Apache 2.0 licencet használó Mistral 7B kiadás felel meg teljes mértékben az OSS szokásos elveinek. Ez érdekes dilemmát eredményez: ahhoz, hogy egy nyílt kiadású mesterséges intelligencia platformhoz felelős felhasználási követelményeket csatoljunk, le kell mondanunk a megfelelő, valódi OSS-típusú terjesztésről. A dilemma egyszerűen arra mutat rá, hogy a mesterséges intelligencia modellek körüli megfontolások eltérőek, és nem szabad azt feltételezni, hogy minden OSS-elv alkalmazható, vagy akár betartható is. Egyrészt az LLM-ek nem csak szoftverekből állnak. Ott vannak az előtanítás előtti adathalmazok, az előtanított modell statisztikai súlyait és torzításait reprezentáló adathalmazok, a modell finomhangolásához használt adathalmazok és egyéb „artefaktumok”. Az eddigi különböző nyílt kiadású modellek közül csak az OLMo 7-B adott ki előképzési adatokat az előképzett modell és a modellsúlyok mellett. Vajon az LLM-ek valóban „nyílt forráskódúak”, ha a működésük teljes körű vizsgálatához és megértéséhez szükséges összes műtárgyat nem bocsátják rendelkezésre?
A dilemma másik oldala, hogy a teljes mértékben közzétett modellek jobban ki vannak téve a rosszindulatú felhasználásnak. Ha valaki úgy véli, hogy a nagy teljesítményű LLM-ek felelősségteljes használata a legfontosabb, akkor talán a nem teljes nyitottság (azaz az adott LLM-hez tartozó összes lehetséges artefaktum rendelkezésre bocsátása) és az OSS-elvekhez való teljes hűség (azaz a felelősségteljes használat követelményeinek beépítése) a jobb út. Az OSS licenc „tisztasága” nem biztos, hogy valódi erény a nyílt kiadású mesterséges intelligencia esetében.
Azok számára, akik ellenzik a nyílt kiadás minden formáját, még a kvázi OSS típusú kiadások is problémásak. Azok a szereplők, akiknek rosszindulatú szándékuk van a nyílt kiadású LLM-ek felhasználására, valószínűleg nem törődnek a felelősségteljes felhasználási korlátozásokkal. Ha egy rosszindulatú szereplőnek szándékában áll a nyílt kiadású LLM-ek bűnös felhasználása, nem valószínű, hogy aggódni fog a licenc betartásának kikényszerítésére irányuló polgári peres eljárások miatt, amelyeket egyébként is nagyon valószínűtlen, hogy a kibocsátó érvényesíthetne ellene. Ez a nézőpont egyenesen a második fő kérdéshez vezet bennünket, mellyel a nyílt kiadású LLM-ek szembesülnek: vajon a nyílt kiadás bármely formája bölcs vagy felelősségteljes-e, tekintettel a rossz szereplők által okozott társadalmi károk hatalmas lehetőségére.

A nyílt kiadású mesterséges intelligencia platformok veszélyei
Az LLM-ek veszélyes vagy társadalmilag káros alkalmazásai számosak. Ezeket általában felsorolják a tiltott használatra vonatkozó irányelvek, melyek néhány nyílt kiadású modellt, például a Gemmát és a Llama 2-t kísérik. E valószínűsíthető ártalmak közül sok megvalósul, például a pénzügyi csaláshoz, adócsaláshoz, választási beavatkozáshoz, hírességek szexuális kizsákmányolásához és a gyermekbántalmazásról készült generatív képekhez használt mélyreható hamisítványok. Az ilyen jellegű problémák már az LLM-alkalmazások széles körű elérhetőségét megelőzően is léteztek. A nagy teljesítményű LLM-alkalmazások azonban jelentősen felerősítették mind a rosszindulatú incidensek számát, mind azok hatékonyságát.
Természetesen nem minden ilyen incidens származik nyílt kiadási modellekből. Biden elnök mély hamis hangját az Eleven Labs nevű start-up cég hanggeneráló platformjával generálták. Taylor Swift mély hamis képeit a Microsoft Designer AI képgenerátorával hozták létre. (A Microsoft egyik mesterséges intelligenciával foglalkozó mérnöke nemrégiben lépett fel, és arra kérte a Microsoft igazgatótanácsát és az FTC-t, hogy szigorúbban felügyeljék a technológiai vállalatok mesterséges intelligencia termékeit, hogy biztonságosabbá tegyék azokat.) A szabadalmaztatott LLM-ek finomhangolása és összehangolása trükkös, pontatlan feladat. A saját LLM-alkalmazások üzemeltetői sok exploitot nem látnak előre, és csak azután kapják el és kezelik őket, hogy az okos felhasználók kitalálták és bevetették őket. Az iparág megfigyelői mégis bizonyítékot találtak arra, hogy a nyílt kiadási modelleket keresik a bűnözők és csalók, akik szisztematikusan illegális tartalmat kívánnak létrehozni. Ez sokkal hatékonyabb és erőteljesebb, mintha egy védett modellen próbálgatással és tévedéssel találnának ki egy exploitot, majd ezt újra meg kell tennie, amikor az üzemeltető rájön, és leállítja. A gyermekpornográfia elkövetői például nyíltan megvitatják a sötét weben, hogyan használhatják ki a nyílt kiadási modelleket illegális tartalom előállítására. A kérdés tehát nem az, hogy a nyílt kiadási modelleket igazságtalanul emelik-e ki, hanem az, hogy milyen mértékben szolgálhatják a mesterséges intelligencia alkalmazások rosszindulatú célokra történő felhasználását.

A társadalmi hasznosságon túl
A nyílt kiadású modellek társadalmi hasznosságot nyújtanak, különösen abban a tekintetben, hogy a fejlesztők és kutatók új és hatékonyabb módszereket tervezhetnek az LLM-ek finomhangolására, összehangolására és biztonsági képzésére. A jól felszerelt, mesterséges intelligencia szakértelemmel rendelkező (saját vagy vállalkozókon keresztül) rendelkező vállalati alkalmazók a saját egyedi igényeikhez igazíthatják a nyílt kiadási modelleket. Mindezeken túlmenően az OSS-mozgalomhoz kapcsolódó szélesebb körű innovációs előnyök nem valószínű, hogy a nyílt kiadású LLM-ekből származnak, különösen nem olyan módon, hogy az érdemi további versenyt eredményezne. Azokat a közhelyeket, melyek ezeket a szélesebb körű feltételezett előnyöket természetesnek veszik, félre kellene tenni az értelmes vita és a megalapozott politikai döntéshozatal érdekében. A rosszindulatú felhasználás kérdését illetően szélsőséges és nem hasznos a nyílt kiadású LLM-eket a Manhattan Projecthez hasonlítani.
Az LLM-ek általában új határokat nyitnak meg a konstruktív és a rosszindulatú felhasználás előtt egyaránt. Ha az LLM olyan lenne, mint a Manhattan Project, akkor a magánszektor szereplői, akiknek LLM-jük van, nem üzemeltethetnék azokat, nemhogy felajánlanák használatukat a nagyközönségnek. A zárt forráskódú LLM-ek sebezhetőek a kihasználásokkal szemben, és az őket üzemeltető, jól felszerelt vállalatok sebezhetőek a hibákkal, a biztonsági résekkel és a manipulációval szemben. Gyakorlati módszerekre van szükségünk az LLM-ek valódi veszélyeinek kezelésére, beleértve a nyílt kiadású LLM-eket is anélkül, hogy nukleáris fegyverként kezelnénk őket, és a kormányzati ügynökségeken kívül bárki számára megtiltanánk a használatukat.

Tehát hol maradunk? A vita sokban hasonlít az Egyesült Államokban folyó fegyverellenőrzési vitára. Azok, akik a fegyverek legális és szabadon hozzáférhetővé tételét támogatják, azzal érvelnek, hogy az emberek embereket ölnek, nem pedig fegyvereket, és a végrehajtási erőfeszítéseknek inkább az emberek bűnözői magatartására kellene összpontosítaniuk, nem pedig a fegyverek elérhetőségének akadályozására. A másik oldalon a pártolók rámutatnak, hogy a fegyverek (különösen a nagyobb teljesítményű, halálos képességekkel rendelkező fegyverek) túlzott bősége táplálta az erőszak válságát, és nem hagyhatjuk ki magukat a fegyverek elérhetőségét a politikai egyenletből. Egyik oldal sem „téved”, de a szélsőségekhez való ragaszkodás nem volt hasznos, és a fegyveres halálesetek csökkentését célzó, józan ész által vezérelt reformok útjában állt. Kétségtelen, hogy a fegyvervita erősen politikai jellege miatt az analógiaként való felhasználása provokatív, mivel az LLM nyílt kiadásáról szóló vitában részt vevőknek nem biztos, hogy tetszik a fegyverekről szóló vita azon álláspontja, mellyel a nézeteiket analóg módon hasonlítják össze. Nem az a célunk, hogy bosszantsuk bárkit is, hanem az, hogy a közhelyektől és a pontatlan történelmi összehasonlításoktól eltávolodva árnyaltabb gondolkodásra ösztönözzünk a kérdésről mindenkit.
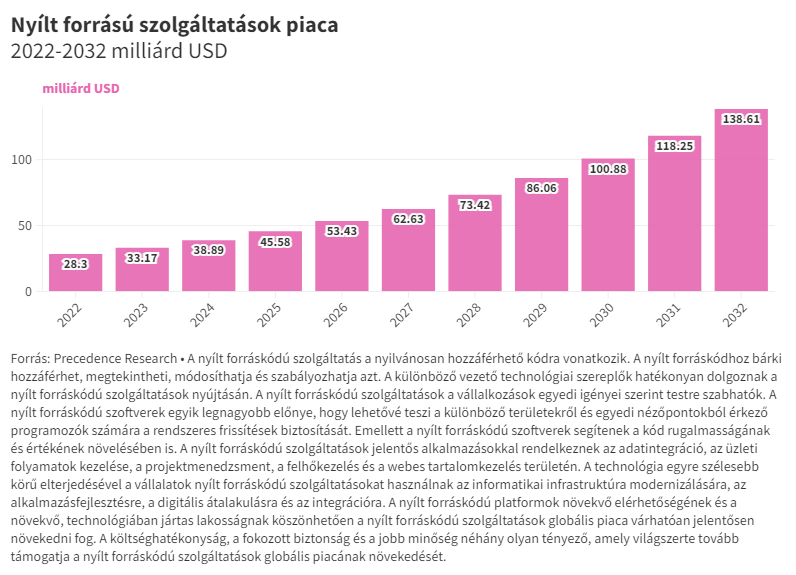
(Kiemelt kép: Unsplash+)






