(Kiemelt kép: Unsplash)
Valójában az adatminőség lehet a kulcsa az MI-képességek következő ugrásszerű fejlődésének. A „TinyStories: How Small Can Language Models Can Be and Still Speak Coherent English?” című tanulmányban Ronen Eldan és Yuanzhi Li kutatók kis, 10-100 millió paraméteres nyelvi modelleket képeztek a GPT-3 által generált egyszerű, összefüggő történetekből álló szintetikus adathalmazon. A GPT-3-hoz hasonló, több milliárd paraméterrel rendelkező modellekhez képest apró méretük ellenére ezek a „TinyStories”-modellek meglepően koherens folytatásokat tudtak generálni a felszólításokból. A kulcs a képzési adatokban rejlett, bár mennyiségük kicsi volt, minőségük rendkívül kifinomult.

Ez a téma visszaköszönt a „Textbooks Are All You Need” című videóban, ahol a phi-1 nevű 1,3 milliárd paraméteres modell a legkorszerűbb kódolási benchmark eredményeket érte el, melyek összehasonlíthatóak a 10-100x nagyobb modellekkel. A phi-1-et mindössze 7 milliárd kiváló minőségű tokenen képezték, melyeket kézzel válogattak és szintetizáltak, hogy hasonlítsanak a tankönyvi példákhoz. Az adatszűrési és generálási folyamat kifejezetten a sokszínűséget, az egyensúlyt és az oktatói tartalmat célozta meg. Végül, a „Textbooks Are All You Need II” című vizsgálatban a phi-1.5 modell 30 milliárd szintetikus „tankönyvi” adatot tartalmazó token segítségével mutatta be az emberi szintű „józan ész” érvelést. A phi-1.5 kis méretaránya ellenére a phi-1.5 megfelelt vagy meghaladta a 13 milliárd paraméterig terjedő modelleket a józan ész viszonyítási pontjain. A kulcs az volt, hogy a szűrt webes adatok helyett „tiszta lappal”, tankönyvszerű adatokkal indult, ami kevesebb „mérgező” generációt eredményezett.
A Nougat-papír egy másik megközelítést mutat be a kiváló minőségű adatok felhasználására. Modelljüket arra képezték ki, hogy a szkennelt tudományos PDF-dokumentumokat strukturált jelölőszöveggé alakítsa át, visszanyerve a PDF formátumban elveszett szemantikai információkat, különösen a matematikai egyenletek esetében. A PDF-eket az eredeti LaTeX forráskódjukkal párosítva nagyméretű, kiváló minőségű dokumentum-szöveg párokból álló képzési adathalmazt hoznak létre. Ezáltal egy olyan modell jön létre, amely képes PDF-ekbe zárt tankönyvek és kutatási dokumentumok millióinak digitalizálására, felszabadítva a bennük rejlő tudást.
E tanulmányok során a kisebb adathalmazok gondos kurátori kezelése (akár szűréssel, generálással, akár szintézissel) következetesen olyan modelleket eredményezett, melyek a súlycsoportjukat meghaladóan ütősek voltak. A tanulság egyértelmű: a képzési adatok minősége felülmúlhatja a mennyiséget, és ez lehet a következő határ az új mesterséges intelligencia képességek elérésében. Ahogy a modellek egyre nagyobbak lesznek, a kutatási erőfeszítéseknek a kiváló minőségű adatok beszerzésére és optimalizálására való összpontosítása további áttörésekhez vezethet. A szövegkönyvszerű adatok jobban megtaníthatják az absztrakt gondolkodási készségeket, mint a webes adatok zajos tömege.

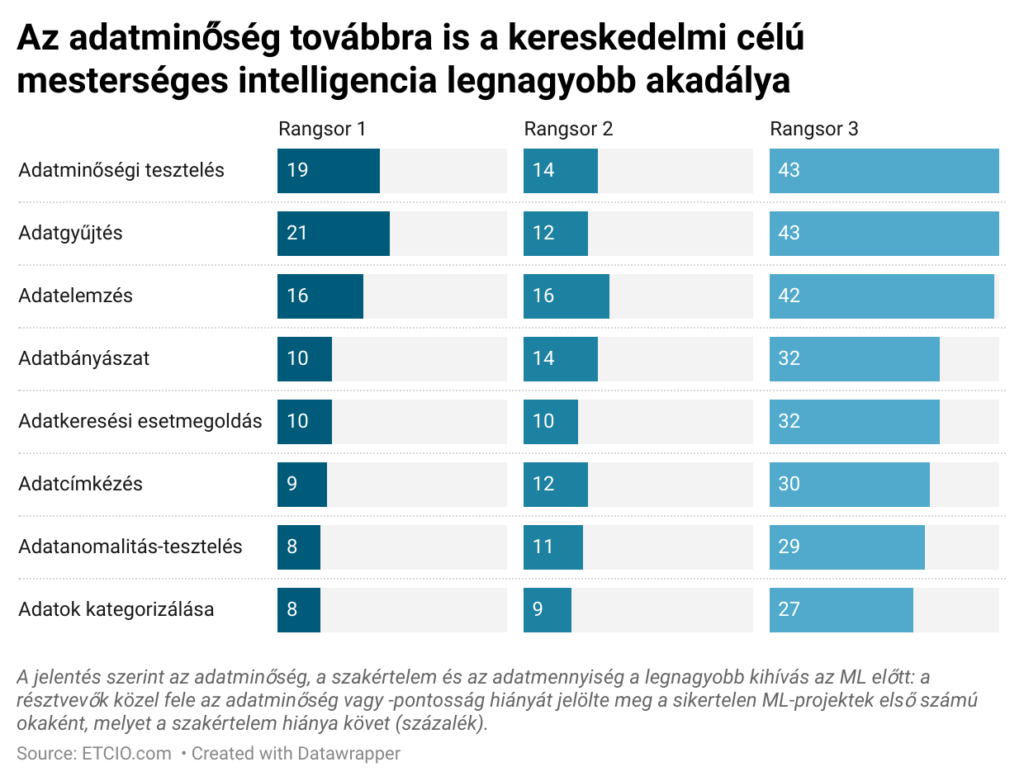
Az adatminőség fontossága a mesterséges intelligencia fejlesztésében
A mesterséges intelligencia fejlődésével a technológiai világ elképesztő felfordulást élt át. A lassulás jelei nem mutatkoznak. Az alkotók számára az adatminőségre való összpontosítás kritikusabb, mint valaha, mivel az MI tovább fejlődik. A pontatlan eredmények és az instabil MI-végrehajtás a gyenge minőségű adatok következményei. A mesterséges intelligencia az elmúlt években egyre inkább előtérbe került. A szervezetek, a hatóságok és az emberek egyaránt kihasználják az MI-technológiát, hogy döntéseket hozzanak, produktívabbá váljanak, és jobb ügyfélszolgálatot nyújtsanak. Az MI-modellek létrehozásához használt adatok minősége azonban kulcsfontosságú ahhoz, hogy ezek a törekvések sikeresek legyenek. Ha az adatok kiváló minőségűek, az MI-modellek pontos és megbízható előrejelzéseket tudnak készíteni. Ez a pontosság szükséges ahhoz, hogy a vállalatok megalapozott döntéseket hozhassanak, és biztonsággal cselekedhessenek. Ezzel szemben, ha az adatok rossz minőségűek, az MI-modellek pontatlan előrejelzéseket fognak eredményezni, amelyek hibás döntéseket és erőforrás-pazarlást okozhatnak.
Vegyünk egy olyan vállalatot, mely egy MI-modelltől függ a vásárlói akciók előrejelzésében. A modell előre jelzi, hogy egy bizonyos ügyfél nagy valószínűséggel megvásárol egy terméket, és a cég nagy mennyiségű erőforrást fordít arra, hogy megpróbálja népszerűsíteni az árucikket ennek a fogyasztónak. A fogyasztó azonban nem érdeklődik a termék iránt, és a vállalat erőfeszítései kárba vesznek. Ez a helyzet elkerülhető lett volna, ha a mesterséges intelligencia modell pontos és kiváló adatokkal rendelkezik. A kiváló minőségű adatok továbbá erősítik a mesterséges intelligencia modellek megbízhatóságát, ami hozzájárul ahhoz, hogy a felhasználók által jobban elfogadják azokat.
Ez pedig jobb döntéshozatalt eredményez, és elősegíti az ügyfelek hűségét és bizalmát. Ez a szempont előnyösen befolyásolhatja a szervezet hírnevét és nyereségét. Ahogy az MI-technológia egyre inkább beépül a mindennapi életünkbe, az adatminőség még nagyobb jelentőséggel bír majd. A jó minőségű adatok szolgáltatásának és az adatok helyességének garantálására vonatkozó követelmény, különösen olyan összefüggésekben, mint a gépi tanulás és a mélytanulási modellek, kiemelkedő fontosságú lesz az MI fejlődése szempontjából.

Hatékony döntéshozatal
A kiváló minőségű adatok rendkívül hasznosak lehetnek az MI fejlesztése során, mivel hatékonyabb döntéshozatalt biztosítanak. Egy hibásan működő, hibás vagy részleges adatokkal rendelkező MI-rendszer hajlamos hibás döntéseket hozni, ugyanakkor a pontos és megbízható adatok bevonásával az MI-modellek nagy mennyiségű adatot képesek gyorsan feldolgozni, hogy a legjobb megvalósítható megoldáshoz jussanak. Ez különösen fontos az olyan kritikus területeken, mint az egészségügy és a pénzügy, ahol a mesterséges intelligencia döntései nagy hatással lehetnek az emberekre. Egy példával élve, egy kórházban egy pontos és alapos adatokkal betanított mesterséges intelligencia rendszer segíthet az orvosoknak abban, hogy gyorsabban jussanak pontos diagnózishoz, ami a betegek jobb kimeneteléhez, sőt talán még életmentő forgatókönyvekhez is vezethet. Egyéni szemszögből nézve az adatminőség nagyban befolyásolhatja a mindennapi életünket. Kapott már olyan javaslatot egy MI-alapú szolgáltatástól, melynek nem volt értelme? Például egy olyan terméket ajánlott, amelyet már megvásárolt, vagy egy olyan filmet, mely nem tetszett Önnek?
Az ilyen esetek hihetetlenül irritálóak és idegesítőek lehetnek, pedig a megfelelő adatokkal az ilyen típusú ajánlások testre szabhatók és pontosak lehetnek, javítva az általános felhasználói élményt. Emellett az adatkezelésben és minőségbiztosításban jártas szoftverfejlesztők alkalmazása elengedhetetlen az MI-algoritmusok pontosságának és megbízhatóságának biztosításához. Alapvetően a magas minőségű adatokkal történő hatékony döntéshozatal az életünk termelékenységének javításáról szól. Ha megbízható adatokon alapuló MI-modellekben bízunk, időnket és szellemi energiánkat olyan ügyekre fordíthatjuk, melyek valóban jelentőséggel bírnak számunkra. Ki tudja, egy nap talán még a döntéshozatalt is átveszi helyettünk az MI.

Csökkentett elfogultság
A mesterséges intelligencia előállításával kapcsolatos egyik legsürgetőbb probléma az előítéletesség valószínűsége. Ez arra utal, hogy az MI-keretrendszerek hajlamosak bizonyos osztályok vagy egyének felé hajlamot mutatni etnikai hovatartozásuk, nemük vagy más egyéni tulajdonságaik alapján. Ha a mesterséges intelligencia egyoldalú, az hosszú távú és kedvezőtlen hatással járhat, és a foglalkozási esélyektől kezdve az egészségügyi ellátáshoz való hozzáférésig mindent befolyásolhat. Következésképpen elengedhetetlenül fontos annak garantálása, hogy a mesterséges intelligencia rendszerek a lehető legpártatlanabbak legyenek, amennyire az ésszerűen elvárható. A mesterséges intelligenciában az előítéletesség csökkentése a keretrendszer által felhasznált információk minőségének javításával kezdődik. Ha a mesterséges intelligenciamodelleket magas színvonalú adathalmazokon készítik el, kevésbé hajlamosak elfogultságokat létrehozni. Ennek az az oka, hogy a modellek elkészítéséhez felhasznált információk egyre inkább a valós világot mutatják be, és kevésbé hajlamosak olyan rejtett elfogultságokat tartalmazni, melyek befolyásolhatják a mesterséges intelligencia döntéseit.
Az egyoldalú mesterséges intelligencia keretrendszerek hatásának egyik példája az egészségügyi ágazatban volt tapasztalható. A Science című szaklapban megjelent vizsgálat megállapította, hogy egy algoritmus, amelynek célja az volt, hogy felismerje a komplex orvosi ellátásra szoruló, magas kockázatú betegeket, végül a fekete betegek ellen szegregált. Ez azért következett be, mert az algoritmust olyan adathalmazok alapján készítették el, amelyek nem a teljes népességet tükrözték, ami torzított eredményekhez vezetett.
Az előítéletek csökkentése az MI-rendszerekben nem csak arról szól, hogy politikailag helyesnek kell lenni, hanem arról is, hogy garantálni kell, hogy az általunk létrehozott innováció ésszerű és mindenki számára egyenértékű legyen. Azzal, hogy a mesterséges intelligencia fejlesztése során az információminőséget helyezzük előtérbe, egyre pontosabb, pontosabb és megbízhatóbb rendszereket hozhatunk létre. Végső soron ez segít majd egy olyan kiváló jövő kialakításában, melyben a mesterséges intelligencia valóban az egész társadalom hasznára válhat. Az MI-fejlesztés speciális készségeket és tudást igényel, ezért kulcsfontosságú, hogy elkötelezett MI-fejlesztőket alkalmazzunk, akik képesek létrehozni és optimalizálni az algoritmusokat.

Jobb ügyfélélmény
A rendkívüli ügyfélkiszolgálás biztosítása a különböző iparágak vállalkozásainak egyik legfontosabb prioritása. Az MI terjedésével a vállalkozások különböző módokon próbálkoznak az adatok felhasználásával az ügyfélélmény testreszabására és fejlesztésére. De nagyon fontos megérteni, hogy az MI-modellek tanításához használt adatok minősége rendkívül fontos a figyelemre méltó ügyfélélmény nyújtásához. Gondoljunk vissza egy olyan helyzetre, amikor szerencsétlen „találkozásunk” volt egy vállalat chatbotjával. Talán feltettünk egy alapvető kérdést, a chatbot azonban közömbös és nem odaillő választ adott. Biztosan elkeserítő volt, nem igaz? Ennek oka, hogy a chatbotot nem első osztályú adatokkal képezték ki, és ezért nem tudta megérteni a kérdését.
Aztán gondoljon egy mesterséges intelligencia által vezérelt személyes vásárlási segédre, mely megérti a stílusunkat, hajlamainkat és pénzügyi terveinket. Olyan termékeket ír fel, melyeket értékelnének, és a pénztári folyamat problémamentes lenne. Olyan, mintha egy privát stylist állna mindig rendelkezésünkre! Ez csak azért lehetséges, mert a mesterséges intelligenciamodellt kiváló adatokkal instruálták, melyek pontosan tükrözik a preferenciáinkat. Következésképpen a vállalkozások számára elengedhetetlen, hogy garantálják az MI-fejlesztés során felhasznált adatok minőségét, kifejezetten akkor, amikor a jobb ügyfélélmény nyújtásáról van szó. Nagyszerű adatokkal a szervezetek egyénre szabhatják a kapcsolatokat, előre láthatják az ügyfelek igényeit, és proaktív ügyfélszolgálatot nyújthatnak. Ez növeli az ügyfélélményt, ösztönzi az ügyfelek elkötelezettségét.

Javított működési hatékonyság
A kiváló kaliberű adatok kihasználása a mesterséges intelligencia előmozdítása érdekében a működési hatékonyság javulását eredményezi. Ha a pontos és releváns információk egy MI-rendszer sarokköveként szolgálnak, számos folyamat és feladat automatizálható, ami felgyorsítja a folyamatot és garantálja annak megbízhatóságát. Az ellátási lánc irányítása kényelmesebbé válik, míg a fogyasztói szolgáltatási protokollok optimalizálódnak, ami olyan hatékonyságot eredményez, amely a vállalkozásoknak versenyelőnyt biztosíthat a mai versenyképes üzleti környezetben. A mesterséges intelligenciával és a legmagasabb minőségű adatokkal a korábban az összetett vállalkozások kezelésére és a tevékenységeket késleltető és a vállalkozásnak költséget okozó esetleges hibák minimalizálására használt erőforrások máshol jobban kihasználhatók.
A műveletek hatékonysága nem egyszerűen a munka gyors elvégzésére utal, hanem a végeredmény minőségének javulását is jelenti. A kifinomult technikák alkalmazásával a szervezetek kívánatosabb eredményeket garantálhatnak, ami hozzájárul a fogyasztók nagyobb elégedettségéhez, a személyzet magas fokú elkötelezettségéhez és egy erősebb vállalati egységhez. Ezért, amikor figyelembe vesszük a kifogástalan adatok előnyeit a mesterséges intelligencia fejlesztéséhez, azt is figyelembe kell vennünk, hogy ez hogyan jelentheti a hatékonyság feljavított szintjét, mely jobbra változtathatja meg vállalkozásunkat. Ha időt és energiát fordítunk arra, hogy az adatok kiváló minőségűek legyenek, az segíthet vállalkozásunknak abban, hogy élenjáróvá váljon, és utat mutasson egy sikeresebb és produktívabb jövő felé.

Szabályozási megfelelés
A mesterséges intelligencia területén a szabályozási megfelelés kulcsfontosságú szempont, melyet a legnagyobb komolysággal kell kezelni. Mivel számos vállalat ma hirtelen az MI felé fordul, hogy előnyhöz jusson riválisaival szemben, a jogalkotók és a szabályozó hatóságok egyre szigorúbbak, amikor a fejlesztés etikus és egyenes vonalú voltának biztosításáról van szó. Ezen irányelvek figyelmen kívül hagyása komoly jogi következményekkel, büntetésekkel és hírnévkárosodással járhat. A szabályozások betartása érdekében a szervezeteknek be kell tartaniuk az adatbiztonság, a magánélet védelme, az adatvédelem és az etika tekintetében hozott törvényeket. A GDPR és a CCPA például megköveteli a vállalatoktól, hogy megvédjék a fogyasztói adatokat, és a felhasználóknak nagyobb ellenőrzést biztosítsanak saját személyes adataik felett. Ezeknek a protokolloknak a kihagyása jelentős bírságokat, a közbizalom csökkenését és a vállalkozás tekintélyének romlását jelentheti.
Érzelmi szempontból a szabályozási megfelelés biztosítja, hogy az MI-rendszerek ne mutassanak elfogultságot bizonyos csoportokkal vagy emberekkel szemben. Ennek elérése érdekében az MI-modelleket megfelelő adatokkal kell kifejleszteni, tesztelni és validálni kell a kívánt eredményekre, és optimalizálni kell az ideális teljesítményre. Ennek eléréséhez elengedhetetlen a valós forgatókönyveket tükröző minőségi adatok gyűjtése, és olyan változatos adathalmazok bevonása, melyek figyelembe veszik az olyan jellemzőket, mint a faji, etnikai, nemi és életkori hovatartozás. Végső soron a szabályozási megfelelési irányelvek betartása nemcsak a bajok elkerülését jelenti, hanem olyan mesterséges intelligencia-rendszerek létrehozását is, amelyek elősegítik az etikai elveket, az átláthatóságot és a sokszínűséget. A megfelelési szabályok betartásával a vállalkozások olyan MI-modelleket hozhatnak létre, amelyek jobb ügyfélélményt, nagyobb adatbiztonságot, fejlett üzleti meglátásokat eredményeznek, és védelmet nyújtanak a váratlan kimenetelekkel szemben. Ezért a szabályozási megfelelés elérése és a mindenki számára előnyös MI-modellek kifejlesztése érdekében elengedhetetlen a kiváló minőségű adatokba való befektetés.

Fokozott adatbiztonság
Az adatbiztonság az egyik legsürgetőbb kérdés, mellyel a vállalkozásoknak manapság szembe kell nézniük, a kibertámadások egyre növekvő kockázata miatt. A biztonság megsértésének elkerülése érdekében kiemelten fontos garantálni, hogy az MI-modellekben alkalmazott adatok naprakészek és pontosak legyenek. A megerősített adatbiztonsággal a vállalatok képesek megvédeni ügyfeleik adatait és saját magánadataikat. Ez nemcsak a hírnevüket biztosítja, hanem csökkenti a pénzbeli veszteségeknek való kitettségüket is. Semmi sem lehet elkeserítőbb, mint tudni, hogy személyes adatainkat bűnözők elvették és visszaéltek velük. Ez az oka annak, hogy az adatbiztonság érzelmi kérdés; nemcsak a pénzről vagy a technológiáról szól, hanem a kibertámadások érzelmi utóhatásairól is. A maximális biztonság érdekében érdemes megfontolni a „full-stack” fejlesztők felbérlését, mivel ők jól felszereltek a teljes szoftverfejlesztési folyamat kezelésére, a front-end tervezéstől a back-end adatfeldolgozásig, így „értékes eszközök” az MI-projektek számára.
Továbbá a jobb adatbiztonság segít megvédeni a belső veszélyektől is. Az adatok pontosságának és konzisztenciájának biztosításával a vállalkozások jobban képesek gyorsan és hatékonyan felderíteni a csalárd viselkedést, melyet egyébként a hibás vagy hibás adatok tennének lehetővé. Továbbá az MI-modellek használatával az adatok elemzése során azonosíthatók a potenciális biztonsági gyenge pontok, melyekkel a jövőbeni visszaélések megelőzése érdekében foglalkozni lehet. Mindent egybevetve, a fejlett adatbiztonság az MI-fejlesztés kulcsfontosságú eleme. Nem pusztán pénzügyi kérdésről van szó, hanem sokkal inkább az egyének magánadatainak védelméről és az érzelmi sérelmek megelőzéséről. Mivel a vállalkozások egyre inkább az MI-ra támaszkodnak, az adatminőség és az adatbiztonság szükségessége csak tovább fog erősödni.