(Kiemelt kép: Unsplash+)
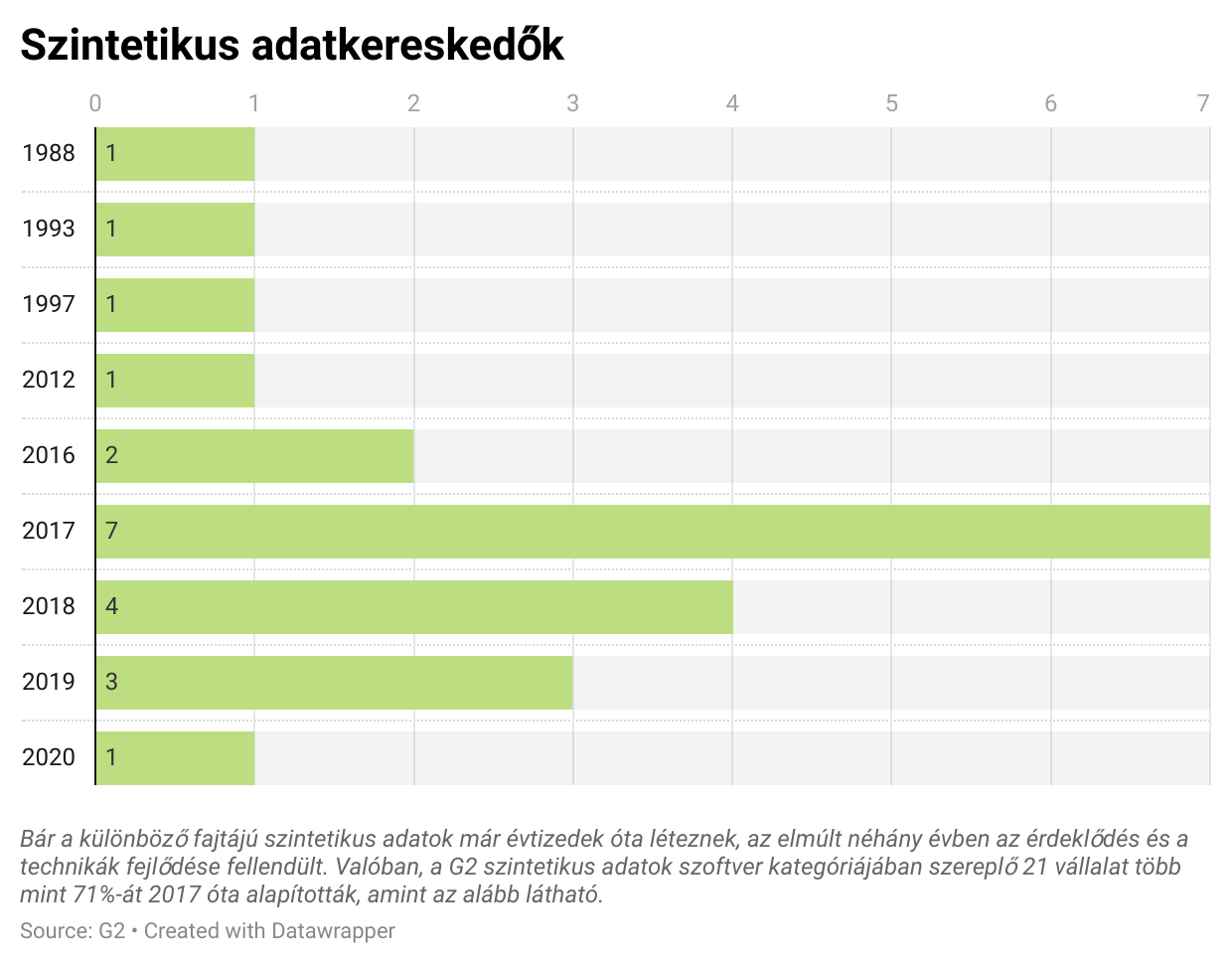
A szintetikus adatok olcsóbban vagy könnyebben beszerezhetők, mint a valós adatok (ha nem így van, akkor valószínűleg nem is kellenek). Ha a valós adatok beszerzése nem megvalósítható, a szintetikus adatok némi reményt adnak arra, hogy a kívánt automatizálási megoldást mégis meg tudjuk építeni. A szintetikus adathalmaz tervezése felett nagyobb a kontroll, mint a valós világbeli adathalmazé felett (ez hátrány lehet, ha nem vigyázunk viszont). A szintetikus adatok nagyszerűek lehetnek bármiféle hibakereséshez, különösen a rendszerünk azon képességének stresszteszteléséhez, hogy képes-e kezelni a kiugró értékeket és furcsa anomáliával rendelkező adatbázisokat. Az MI világában ma az adat a király. Ez hajtja a mélytanuló gépeket, melyek a kihívást jelentő valós MI-problémák megoldásának legmegfelelőbb módszerévé váltak. Minél több jó minőségű adat áll rendelkezésünkre, annál jobban teljesítenek a mélytanulási modelljeink. A technológia nagy ötösfogata: a Google, az Amazon, a Microsoft, az Apple és a Facebook mindannyian elképesztő helyzetben vannak ahhoz, hogy ezt az ínséget ki is használják. Ők hatékonyabban és nagyobb léptékben tudnak adatokat gyűjteni, mint bárki más, egyszerűen a bőséges erőforrásaiknak és a nagy teljesítményű infrastruktúrájuknak köszönhetően. Ezek a technológiai óriáscégek az Öntől és a szolgáltatásaikat használó legtöbb ismerősétől összegyűjtött adatokat használják fel a mesterséges intelligenciájuk képzésére. Az e vállalatok által felhalmozott hatalmas kép- és videó-adathalmazok erős versenyelőnnyé váltak, egy olyan „vizesárokká”, mely megakadályozza, hogy a kisebb vállalkozások betörjenek a piacukra. Egy induló startup vagy egy magánszemély számára, aki lényegesen kevesebb erőforrással rendelkezik, nehéz elegendő adatot szerezni ahhoz, hogy felvegye a versenyt, még akkor is, ha a terméke nagyszerű. A jó minőségű adatok beszerzése mindig költséges mind időben, mind pénzben, ez két olyan erőforrás, melyet a kisebb szervezetek nem engedhetnek meg maguknak, hogy bőkezűen költsenek. Ezt az előnyt a szintetikus adatok piaci megjelenése megdöntheti. Ez megzavarja a jelenlegi status quo-t, hogy bárki képes szintetikus adatokat létrehozni és felhasználni a számítógépek képzésére számos felhasználási esetben, többek között a kiskereskedelemben, a robotikában, az autonóm járművekben, a kereskedelemben és még sok másban.

Mi is az a szintetikus adat?
A szintetikus adatok olyan számítógép által generált adatok, melyek a valós adatokat utánozzák; más szóval olyan adatok, melyeket nem ember, hanem számítógép hoz létre. A szoftveres algoritmusokat úgy lehet megtervezni, hogy valósághű szimulált vagy „szintetikus” adatokat hozzanak létre. Talán már találkozott a Unity vagy az Unreal Engine játékmotorokkal, melyek megkönnyítik a videojátékok és virtuális szimulációk létrehozását. Ezek a játékmotorok nagy méretű szintetikus adathalmazok létrehozására használhatók. A szintetikus adatokat aztán felhasználhatjuk a mesterséges intelligenciamodellek betanítására, ugyanúgy, ahogyan azt a valós adatokkal szoktuk tenni. Az Nvidia nemrégiben megjelent tanulmánya bemutatja, hogyan lehet ezt megvalósítani. Általános eljárásukban szintetikus képeket hoznak létre minden lehetséges változó véletlenszerűségével, beleértve a képi jelenetet, a tárgyakat, a világítás helyzetét és intenzitását, a textúrát, a formákat és a méretarányt. Azzal, hogy ilyen gyorsan és egyszerűen képesek vagyunk jó minőségű adatokat létrehozni, a „kisemberek” ismét játékba lendülnek. Sok korai fázisban lévő startup most már megoldhatja a hidegindítás problémáját (azaz kevés vagy semmilyen adattal indulhat) azáltal, hogy adatszimulátorokat hoz létre, melyek minőségi címkékkel ellátott, kontextus szempontjából releváns adatokat generálnak az algoritmusok betanításához. A szimuláció rugalmassága és sokoldalúsága különösen értékessé és sokkal biztonságosabbá teszi az autonóm járművek képzését és tesztelését ezekben a rendkívül változó körülmények között. A szimulált adatokat könnyebben lehet címkézni is, mivel azokat számítógépek hozzák létre, így sok időt lehet megtakarítani. Olcsó és még olyan hiánypótló alkalmazások feltárását is lehetővé teszi, ahol az adatok beszerzése normális esetben rendkívül nagy kihívást jelentene, például az egészségügy vagy a műholdas képalkotás területén. Az eredendő adatelőnnyel rendelkező inkumbensekkel versenyző startupok számára a kihívás és a lehetőség az, hogy a helyes címkékkel ellátott legjobb vizuális adatokat a számítógépek pontos betanításához a legkülönfélébb felhasználási esetekhez felhasználják. Az adatok szimulálása kiegyenlíti a nagy technológiai vállalatok és a startupok közötti versenyfeltételeket. Idővel a nagyvállalatok valószínűleg szintetikus adatokat is létrehoznak majd a valós adataik kiegészítésére, és egy nap ez ismét megdöntheti a mai játékteret. Mindenesetre a technológia minden eddiginél gyorsabban fejlődik, és a mesterséges intelligencia jövője fényes.

Szintetikus adatokra van szüksége az MI-projektjéhez?
Az adatok a legtöbb mesterséges intelligencia projektben problémát jelentenek. Több projektet is elbukhatunk a jó adatok hiánya miatt. Egyre több vállalkozás így ma az MI-forradalma korában sokkal inkább egy viszonylag új megközelítésre, a szintetikus adatokra támaszkodik. Az MI adatgyűjtési problémájának megoldása mellett a vállalkozásoknak ma az intenzív versennyel is meg kell küzdeniük. A valóság az, hogy az adatgyűjtés költségei magasak, és ez sokakat visszatart attól, hogy egyáltalán belevágjanak. A szintetikus adatok azonban segíthetnek megváltoztatni ezt a helyzetet. A szintetikusan generált adatok segíthetnek a vállalatoknak és a kutatóknak a gépi tanulási modellek betanításához, sőt, akár előtanulmányozásához szükséges adattárakat létrehozni.
Új termékek, új piacok
Azáltal, hogy segít megoldani a mesterséges intelligencia adatproblémáját, a szintetikus adatok technológiája a meglévő üzletágak puszta optimalizálása helyett új termékkategóriák létrehozásában és új piacok megnyitásában rejlik. Ez számos iparágban hatással van az adattudományra. Amellett, hogy lehetővé teszi a munka megkezdését, a szintetikus adatok lehetővé teszik az adattudósok számára, hogy a folyamatban lévő munkát valós és érzékeny adatok bevonása nélkül folytassák. A vállalatok ugyanis mostantól foghatják adattárházaikat vagy adatbázisukat, és létrehozhatják azok szintetikus változatait anélkül, hogy megsértenék a felhasználók adatvédelmét.
Hamis adatok létrehozása
A szintetikus adatok olyan adatok, amelyeket programozottan generálnak. Például tetszőleges jelenetekben lévő tárgyak valósághű képei, amelyeket videojáték-motorok segítségével renderelnek, vagy ismert szövegből beszédszintetizáló modell által generált hang. Fontos elmondani, hogy ez nem különbözik a hagyományos adatnöveléstől, ahol a vágásokat, forgatásokat, forgatásokat és torzításokat arra használják, hogy növeljék az adatok sokféleségét, melyekből a modelleknek tanulniuk kell. Ezek a renderelő-motorok nemcsak tetszőleges számú képet tudnak előállítani, hanem a megjegyzéseket is. A határoló dobozok, szegmentációs maszkok, mélységtérképek és bármilyen más metaadat közvetlenül a képek mellett kerül kimenetre, így egyszerűen lehet olyan pipeline-okat létrehozni, amelyek saját adatokat állítanak elő.
A legtöbb szintetikus adat vizuális
A számítógépes látáson belül lehetséges modelleket képezni számos gyakori feladat elvégzésére, ezek ma már szinte teljes egészében szintetikus adatokon alapulnak. Az objektumdetektálás, szegmentálás, optikai áramlás, pózbecslés és mélységbecslés mind lehetséges a mai eszközökkel. A hangfeldolgozásban és az automatikus beszédfelismerési feladatokban szintén hasznot húzhatnak a generált adatokból. Végezetül a megerősítéses tanulás nagy hasznát vette annak, hogy az irányelveket szimulált környezetben lehet tesztelni, ami lehetővé teszi az önvezető autók és robotok modelljeinek betanítását. A szintetikus adatok előállítása még egy lépéssel továbbléphet, ha ténylegesen olyan szimulált környezetet hozunk létre, amelyben egy megerősítő tanuló algoritmus működhet, és így a műveletei alapján adatfolyamokat generálhat. A kulcskérdés az algoritmus betanításához szükséges szimulált környezet komplexitása.

Mikor használjunk szintetikus adatokat?
A szintetikus adatok segíthetnek felgyorsítani az MI-kezdeményezéseket: az algoritmusok tesztelése szintetikus adatokkal lehetővé teszi a fejlesztők számára, hogy koncepcióbizonylatokat készítsenek, hogy igazolják az MI-kezdeményezések idejét és költségeit. Megmutathatják, hogy az algoritmusok egy adott kombinációja elvileg módosítható a kívánt eredmények elérése érdekében, biztosítékot nyújtva arra, hogy a teljes fejlesztési ciklushoz kapcsolódó költségek nem vesznek kárba, és megadja a szükséges önbizalmat az előrelépéshez. A vállalatok tesztelési célokra gyorsan nagy méretű, tökéletesen címkézett adathalmazokat tudnak kialakítani az igényeknek megfelelően. Továbbá, ezek az adatok ezután iteratív teszteléssel módosíthatók és javíthatók, hogy a legnagyobb valószínűséggel sikeresek legyenek a későbbi adatgyűjtési műveletek során. Az egyik gyakori probléma, amely akkor fordul elő, ha túl sok egy bizonyos címke a képzési adatokban, ez a „túlillesztés”. Ez megbízhatatlan eredményeket hoz létre, amikor a valós használat során szembesülünk vele. A torzítás egy másik probléma, amely az összegyűjtött adatokból származik, melyek nem képviselik megfelelően a valóságban előforduló különbségek teljes skáláját. A szintetikusan generált adatkészletek megbízható és költséghatékony módot biztosítanak e problémák korrigálására és kiegyensúlyozott adatkészlet garantálására. A szintetikus adatok felhasználhatók konkrét esetek megbízható generálására is. Például ritka időjárási események, berendezések meghibásodása, járműbalesetek vagy ritka betegségtünetek szimulásához. A szintetikus adatok jelenthetik az egyetlen módot annak biztosítására, hogy a mesterséges intelligencia rendszerünk minden eshetőségre felkészüljön, és pontosan akkor teljesítsen jól, amikor a legnagyobb szükség van rá.

Útmutató a hamis adatok különböző fajtáihoz
Ha szeretnénk ma adatokat szerezni vállalkozásunk számára, milyen lehetőségeink vannak? Íme a lehető legdurvább válasz: vagy valódi adatokhoz jutunk hozzá, vagy hamis avagy szintetikus adatokhoz. Vegyünk egy példát arra, hogy ez hogy nézhet ki a gyakorlatban (az emberi magasság mint adat kapcsán).
Duplikált adatok
Lehet, hogy 10.000 „valódi” emberi magasságot már megmértünk a vállalkozásunkban, de 20.000 adatpontot szeretnénk az egy projektünkhöz. Az egyik megközelítés az, hogy feltételezzük, hogy a meglévő adathalmazunk már elég jól reprezentálja a populációt. (A feltételezések mindig veszélyesek, járjunk el óvatosan.) Ekkor egyszerűen megduplázhatjuk az adathalmazt, vagy annak egy részét. Még több adatot kaptunk rögvest. De vajon jó és hasznos adatokról van szó? Ez mindig attól függ, hogy mire van szükségünk. A legtöbb esetben a válasz nem.
Újramintavételezett adatok
Ha már az adatoknak csak egy részének duplikálásánál tartunk, van egy módja annak, hogy egy kis véletlenszerűséget adjunk bele a folyamatba, hogy segítsünk kitalálni, melyik részt válasszuk ki. Használhatunk egy véletlenszám-generátort, hogy segítsen kiválasztani, hogy melyik magasságot válassza ki a meglévő magasságok listájából. Ezt megtehetjük „csere nélkül” is, ami azt jelenti, hogy minden meglévő magasságról legfeljebb egy példányt készítünk.
Bootstrapped adatok
Gyakrabban láthatjuk, hogy a cégek ezt „cserével” csinálják, ami azt jelenti, hogy minden alkalommal, amikor véletlenszerűen kiválasztunk egy magasságot a másoláshoz, azonnal elfelejtjük, hogy ezt tettük, így ugyanaz a magasság bekerülhet az adatkészletünkbe második, harmadik, negyedik stb. másolatként.
Kiegészített adatok
A bővített adatok talán furcsán hangzanak, de léteznek fura metódusai is az adatok bővítésének, de általában, amikor ezt a kifejezést látjuk, azt jelenti, hogy fogtuk az újramintázott adatainkat, és hozzáadtunk némi véletlenszerű zajt. Más szóval, egy véletlen számot generáltunk egy statisztikai eloszlásból, és jellemzően egyszerűen hozzáadtuk az újramintázott adatponthoz. Ennyi. Ez lenne az augmentáció.

Túlmintavételezett adatok
Ha már az adatoknak csak egy részének duplikálásánál tartunk, van egy módja annak, hogy szándékosan erősítsünk bizonyos jellemzőket másokkal szemben. Lehet, hogy a méréseket egy tipikus magyar ICT-konferencián végeztük, így a női magasságok alulreprezentáltak az adatainkban (szomorú, de igaz ez manapság). Ezt nevezzük a kiegyensúlyozatlan adatok problémájának. Vannak technikák az ilyen jellemzők reprezentációjának kiegyensúlyozására, például a SMOTE (Synthetic Minority Oversampling TEchnique), ami nagyjából az, aminek hangzik. A probléma leküzdésének legnaivabb módja az, hogy az újramintavételezést egyszerűen a „kisebbségi” adatpontokra korlátozzuk, és a többit figyelmen kívül hagyjuk. Tehát a példánkban csak a női magasságokat mintavételeznénk újra, míg a többi adatot figyelmen kívül hagynánk. Kifinomultabb növelést is mérlegelhetünk, de továbbra is a női magasságokra korlátozhatja erőfeszítéseinket. Ha még bonyolultabbá akarnánk tenni a dolgot, akkor olyan technikákat kereshetnénk fel, mint az ADASYN (Adaptive Synthetic Sampling).
Edge case adatok
Olyan (kézzel készített) adatokat is kitalálhatunk, melyek teljesen eltérnek mindattól, amit mi (vagy bárki) valaha is látott. Az nagyon buta dolog lenne, ha a valós világ modelljeinek létrehozására próbálnánk felhasználni ezeket, de okos dolog, ha például arra használjuk majd, hogy teszteljük a rendszerünk képességét, hogy furcsa dolgokat is kezelni tudjon. Hogy megtapasztalhassuk, hogy a modellünk (elméletünk vagy rendszerünk) befullad-e, amikor egy kiugró értékkel találkozik, szándékosan készíthetünk szintetikus kiugró értékeket. Tegyünk be egy 3 méteres magasságot, és nézzük meg, „felrobban-e” a rendszer.
Szimulált adatok
Ha már kezdünk megbarátkozni a gondolattal, hogy az adatokat a saját specifikációink szerint állítsuk össze, akkor érdemes egy lépéssel továbbmenni, és létrehozni egy „receptet”, mely leírja az adatállományában szereplő adatok alapjául szolgáló fajta természetét. Ha van véletlen komponens, akkor tulajdonképpen egy olyan statisztikai eloszlásból szimulál, mely lehetővé teszi, hogy meghatározza az alapelveket, ahogyan azokat egy modell (ami csak egy elegáns kifejezés arra, hogy „egy képlet, melyet receptként fogunk használni”) leírja, egy szabállyal arra vonatkozóan, hogy hogyan működnek a véletlen bitek. Ahelyett, hogy véletlenszerű zajt adnánk hozzá egy meglévő adatponthoz, mint a szokásos adatnövelési technikák, hozzáadhatjuk a zajt egy olyan szabálykészlethez, melyet kitaláltunk, akár egy kapcsolódó adathalmazzal végzett statisztikai következtetéssel.
Túlmutatva az egyes számokon
Magasságok? Várjunk csak, egy olyan adathalmazt kérünk, amiben egyszerre csak egy magasság van? Milyen unalmas! Milyen „floppy lemezes” és fapados korszak. Ezt nevezzük egyváltozós adatnak, és manapság ritkán látni ilyet a természetben összegyűjtve. Most, hogy hihetetlen tárolókapacitással rendelkezünk, az adatok sokkal érdekesebb és összetettebb formában érkezhetnek. Nagyon olcsó, hogy néhány extra jellemzőt is megragadjunk a magasságokkal együtt, ha már itt tartunk. Rögzíthetnénk például minden egyes személy frizuráját, így adathalmazunkat kétváltozóssá tehetnénk. De miért állnánk meg itt? Mi lenne, ha az életkort is feljegyeznénk, így adataink többváltozósak lennének? De manapság „megvadulhatunk”, és mindezt kombinálhatjuk képi adatokkal (fotózzuk le az ügyfeleinket például a magasságmérés közben) és szöveges adatokkal. Ezt hívjuk multimodális adatoknak, és ezt is szintetizálhatjuk!

Legyünk óvatosak, amikor szintetikus adatokról van szó
A szintetikus adatok nem mindig jelentenek tökéletes megoldást. Valójában a szintetikus adatok általában nem alkalmasak gépi tanulási felhasználási esetekre, mivel a legtöbb adatkészlet túlságosan összetett ahhoz, hogy megfelelően „hamisítsuk”. Továbbá a szintetikus adatok használata a fejlesztési fázisban félreértésekhez is vezethet azzal kapcsolatban, hogy a gépi tanulás modellje hogyan fog teljesíteni a tervezett adatokkal, ha egyszer már a „termelésbe” került van. Sőt, ha a szintetikus adatokkal képzett modell rosszabb teljesítményt nyújt, mint az „eredeti” adatokkal képzett modell, a döntéshozók elutasíthatják a munkáját, még akkor is, ha a modell megfelelt volna az igényeiknek. Ha a szintetikus adatokkal képzett modell jobban teljesít, mint a tervezett adatokkal képzett modell, irreális elvárásokat támaszthat. A legtöbbször ritkán tudjuk, hogy modellünk teljesítménye hogyan fog változni, ha egy másik adatkészlettel képezzük ki, amíg nem képezzük ki az adott adatkészlettel. A projekt jellegétől függően úgy vélhetjük, hogy ha elég jól értjük a tervezett adatokat ahhoz, hogy egy lényegében tökéletes szintetikus adathalmazt hozzunk létre, akkor értelmetlenné válik a gépi tanulás alkalmazása, mivel már előre tudjuk jósolni a körvonalakat. A képzéshez használt adatoknak véletlenszerűnek kell lenniük, és arra kell használni őket, hogy lássuk, milyen lehetséges kimenetelei vannak ezeknek az adatoknak, nem pedig arra, hogy megerősítsük azt, amit már tudunk.

A szintetikus adatok korlátai
Bár a szintetikus adatok segítségével sokféle előnyt lehet levezetni, ez nem mentes a kihívásoktól. Annak ellenére, hogy optimista vagyok a szintetikus adatok jövőjét illetően az ML-projektek számára, van néhány korlátozás. Ezek közül néhány technikai jellegű, míg mások üzleti vonatkozásúak. Az olyan egyszerű feladatok, mint például „azonosítsd ezt a bizonyos csomagolást” könnyűek, de az olyan összetettebb feladatok, mint például „ismerd fel a ritka állatok több száz faját” még mindig nehézségekbe ütköznek. Üzleti szempontból a szintetikus adatok hosszú távon sok modellt árucikké tesznek. Bár sok előrelépés történt ezen a területen, az egyik továbbra is fennálló kihívás a szintetikus adatok pontosságának garantálása. Biztosítanunk kell, hogy a szintetikus adatok statisztikai tulajdonságai megegyezzenek az eredeti adatok tulajdonságaival.