Mesterségesintelligencia-fejlesztőknek egyre komolyabb adatmennyiségre van szükségük terebélyesedő modelljeik gyakoroltatásához. Ezeknek a vizuális, hang, szöveges, multimédiás anyagoknak a forrásai különféle médiafelületek, köztük nagy kiadók, híroldalak, online sajtótermékek hatalmas archívumai.
Elsősorban szövegekről van szó, a neves médiaorgánumok termékei zömükben jól megírt, kiváló minőségű, tényellenőrzésen átesett, jelenlegi és közelmúltbeli eseményekről szóló, széleskörű érdeklődésre számot tartó tudósítások, elemzések stb.
Az archívumok licencelésével fejlesztők jogi következmények, pereskedések és büntetések kockázata nélkül férhetnek hozzá csomó olyan adathoz, információhoz, amire nagy szükségük van. A hírforrások újrafeldolgozás célú elérhetővé tételével a rajtuk tanuló chatbotok jobban teljesítenek, korábbi generációiknál hitelesebbek és megbízhatóbbak lesznek.
Jogos vagy jogtalan az archívumhasználat?
A generatív mesterséges intelligencia térnyerésével, a ChatGPT mögötti és a Microsofttal tandemben ténykedő OpenAI vált az MI kulcsszereplőjévé. Pletykák szerint a Sam Altman által vezetett vállalat keresőszolgáltatást tervez. Márpedig chatbothoz és kereséshez (és a kettőhöz együtt) egyaránt rengeteg és megbízható forrásból származó adat kell. A híroldalak archívumai tökéletesen megfelelnek a célnak, használatuk egyik törvényes módja a licencelés. Ebben az esetben az adott fejlesztőcég egyértelműen legális forrásokat használ, nem kell a törvényes és a törvénytelen közötti szürkezónában gyűjtögetnie, és a felhasználtakat az eddigi gyakorlattal ellentétben feltüntetheti, mert nem lesz belőle semmi szerzői jogi kellemetlensége.

Sam Altman, az OpenAI vezérigazgatója
Az MI-fejlesztők többsége általában a weben gyűjtöget, innen-onnan szed össze anyagokat, és jogvédett munkák használati engedélye nélkül dolgozik velük. Az Egyesült Államok szerzői jogi törvénye alapján nem egyértelmű, hogy ez szabályos vagy szabálytalan. A vélemények megoszlanak: egyesek a falig védenék, őriznék archívumaikat, míg a másik oldal a szabad használat, nyílt forráskód, nyílt internet mellett érvel. A szabályozók feladata a döntéshozás, köztes megoldás látszik életképesnek, mert túlzott szigorítással a fejlesztéseket lassítanák le, és korlátoznák a versenyt.
New York Times kontra OpenAI
A szerzői jogok egyre több tulajdonosa igyekszik jogi útra, bíróságra vinni a problémát.
A New York Times tavaly decemberben perelte be az OpenAI-t és a Microsoftot, arra hivatkozva, hogy az OpenAI a cikkek modellek gyakoroltatására történő használatával megsértette a szellemitulajdon-jogokat. Idén áprilisban az Alden Global Capital fedezeti alap tulajdonában lévő nyolc amerikai újság hasonló indokok alapján indított pert szintén az OpenAI és a Microsoft ellen.

Gyakorlóadatok
A kiadóktól történő licenceléssel az OpenAI pereskedés nélkül férhet hozzá az anyagokhoz. Előbbiek mindenképpen jobban járnak, míg az utóbbinak ugyan nagyobbak a kiadásai, de a jövőben legalább senki nem kérdőjelezi meg modelljeik jogtisztaságát. Ráadásul, ha elveszítik a valószínűleg évekig eltartó, a technológia gyors fejlődését látva, ítélethirdetéskor talán relevanciáját is elveszítő pereskedést, akkor aztán pláne meg fognak nőni a kiadásaik, sőt, még stigmát is sütnek rájuk. Ugyanakkor a kiadók harcias hozzáállása is inkább tűnik szélmalomharcnak.
A kis fejlesztőcégek járnak rosszul
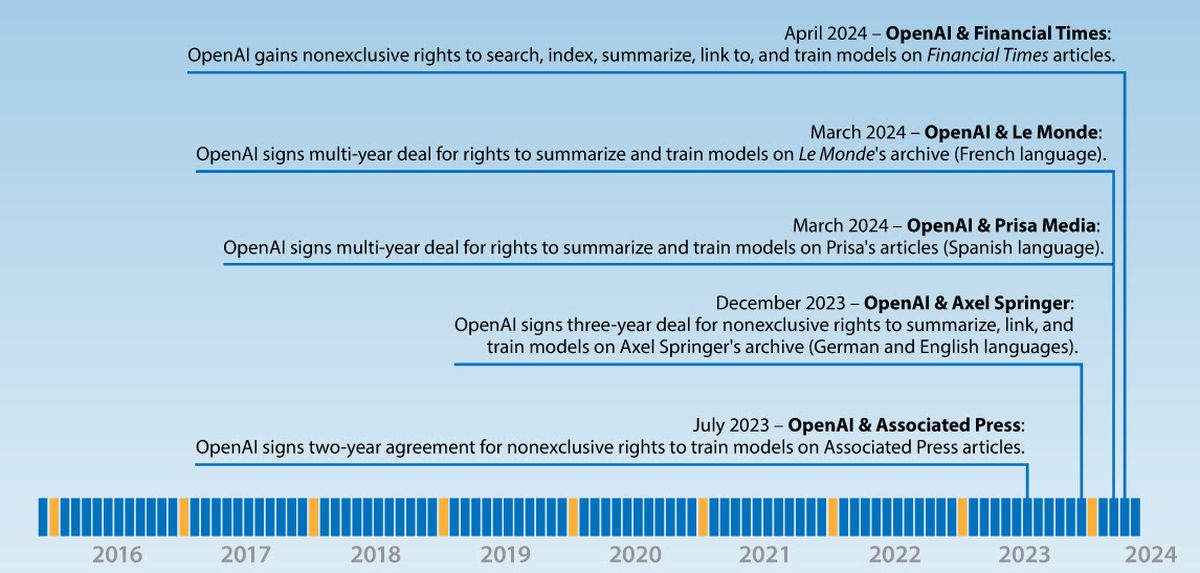
A Financial Times archívum használati licencének ára és a szerződés időtartama sem hivatalos. Egy év alatt ez a fejlesztő ötödik megállapodása nagy kiadókkal, az eddigiek két, három, illetve öt évre szólnak. A korlátokat figyelembe véve, inkább kísérletekről, mint stratégiai lépésekről beszélhetünk. A deal alapján a modellek a kiadó cikkein – a fizetőfal (paywall) mögöttiekkel, tehát online ingyen elérhetetlenekkel is – gyakoroltathatók, és közölhetők az azokból gyűjtött információk.
Az OpenAI így a versenytársak által elérhetetlen anyagokon is gyakoroltathatja modelljeit. Nyilván megint a legkisebb, nyílt forrású versenyzők jönnek ki legrosszabbul az egészből, mert nem engedhetik meg maguknak licencdíjak fizetését. Egyes OpenAI-szerződések ráadásul exkluzívak is, tehát mindenféle versenyt ellehetetlenítenek.
A szerződések
A Financial Times szerződés – a felek stratégiai partnerségnek is nevezik – nem az; kereséshez, indexeléshez és gyakoroltatáshoz ad jogokat. A ChatGPT idézhet, összegezhet és linkelhet anyagokat, de nincs benne semmi kizárólagosság.
Az OpenAI és a média
A francia Le Monde-dal és a spanyol lapokat (köztük az El Paist) birtokló Prisa Mediaval márciusban kötött szerződés a gyakoroltatáshoz és az idézéshez ad (fizetős cikkekre is érvényes) jogokat. A szervezetek az OpenAI francia és spanyol nyelvű híranyagainak kizárólagos szolgáltatói.
2023 decemberében a német nyelvű Bildet és Die Weltet, valamint az angol Politico-t és Business Insidert tulajdonló Axel Springerrel szerződtek három évre, nagyjából nem exkluzívan: a modellek gyakorolhatnak az anyagokon, összegezhetik és linkelhetik azokat – a fizetőseket is. Annyi exkluzivitás mégis van a megállapodásban, hogy az Axel Springer lapok az OpenAI kizárólagos német nyelvű beszállítói.
2023 júliusában az Associated Pres-szel (AP) állapodtak meg nem exkluzív módon két esztendőre. A fizetőfalat nem használó AP nem pontosított hozzáférést kapott az OpenAI technológiáihoz, szakértelméhez, anyagaik összegzési és linkelési jogait viszont szintén nem pontosították.
Képek: DeepLearning.ai, Wikimedia Commons, Flickr



